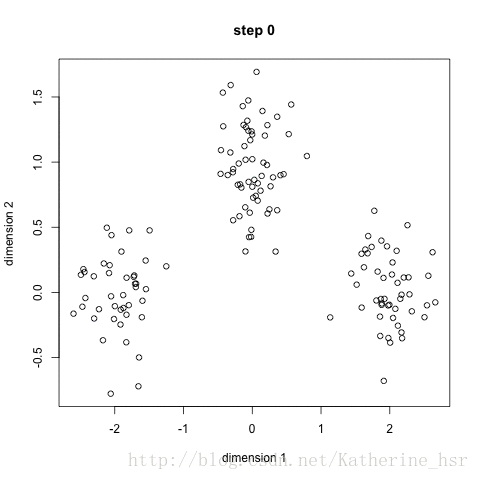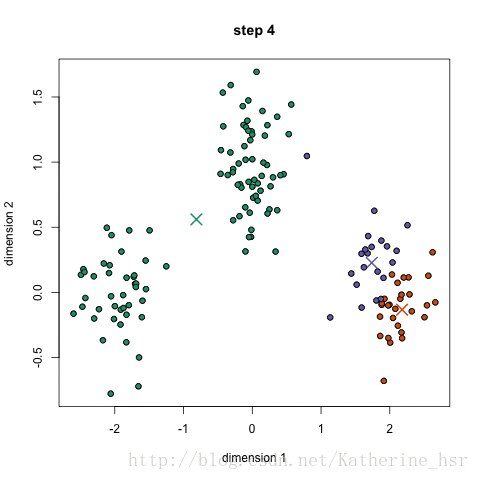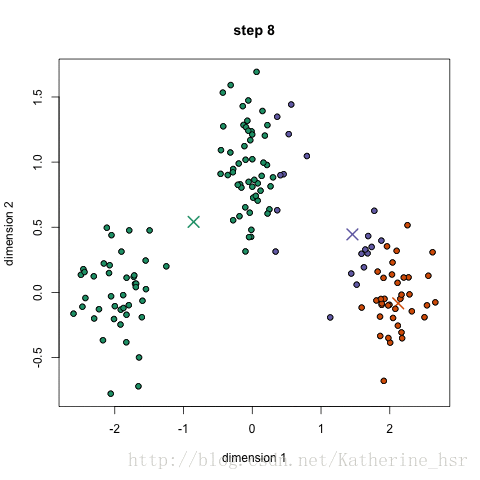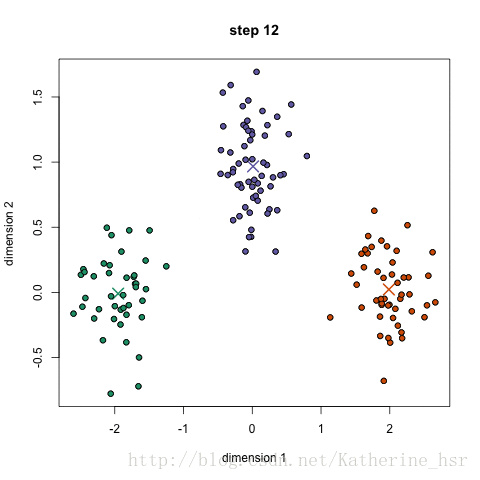
常用聚类算法
聚类:就是把分散的东西,按照相同的类别聚到一起。“物以类聚,人以群分”,它是一种研究,统计的手段,聚类起源于分类,但是不等于分类,聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。本文介绍一些基本的聚类算法,具体的代码实现,后续再跟进,首先了解理论思想。
聚类算法的重点是计算样本项之间的相似度,也叫样本间距的大小。
聚类算法和分类算法的区别是:
分类算法是有监督学习,基于有标注的历史数据进行算法模型构建。比如神经网络大多构成的是分类器,是通过已知标签的数据来调整网络。
聚类算法是无监督学习,数据集中的数据是没有标注的。
K-Means(K均值)聚类
算法简介:
K-means聚类算法算得上是最著名的聚类方法。Kmeans算法是一个重复移动类中心点的过程,把类的中心点,也称重心(centroids),移动到其包含成员的平均位置,然后重新划分其内部成员。k是算法计算出的参数,表示类的数量;K-means可以自动分配样本到不同的类,但是不能决定究竟要分几个类。k必须是一个比训练集样本数小的正整数。有时,类的数量是由问题内容指定的。
总的来讲K-means算法的数学原型来自于线性代数的最优化问题。
基本思想:
给定一个有M个对象的数据集,构建一个具有k个簇的模型,其中k<=M 满足以下条件:
- 每个簇至少包含一个数据对象。
- 每个对象属于且仅属于一个簇。
- 将满足上述条件的k个簇称为一个合理的聚类划分。
简单讲就是把给定的总样本数据分成k个类别,首先给定初始划分,然后通过迭代改变样本和簇的隶属关系,使得每次迭代后得到的簇中各个元素到簇中心的距离变小了。
算法核心思想:
每次迭代维护一个最小的样本到簇中心的距离:假设簇划分为(C{1},C{2},C{3}…C{k}),那么我们需要维护的最小平方误差E为:
二分类: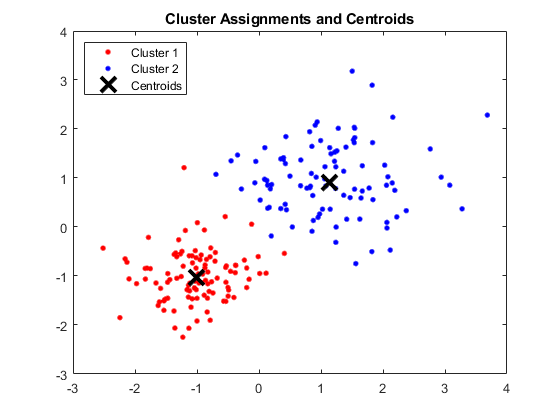
多分类: